

How can you optimize the Googlebot’s caching and indexing process? First, iQuanti SEO expert Dipankar Biswas writes, it’s important to understand the difference between the two.
When the Google crawler comes to your website, it will take a snapshot of each page. This copy is referred to as the cached version of your site.
Caching has a number of benefits for internet users. If a page is unavailable because of internet congestion, a server issue, or a site edit, the page content is still visible in Google’s cache.
Client-side caching, meanwhile, transparently stores site data closer to end-users so future data requests can be served faster, without having to ping the origin server. This reduces server loads while also speeding up users’ browsing experience.
The main reason Google’s crawler uses caching, however, is for indexing.
Once the crawler has grabbed a copy of your page, it will break it down in order to map different search results to different web pages. This broken-down information is referred to as Google’s index. From an outside view, it looks similar to a database. Effectively, though, it’s a gigantic custom map created by and for Google that weighs values, locations, and many other ranking factors.
Simple enough – but modern web design can throw a wrench in the gears of this process.
The main problem that arises is that Google’s cache and index are not always representative of page content, because the Googlebot only scans and ingests plain HTML. In other words, the cached version reflects the HTML page that gets served, not the rendered version that the user sees.
If a site uses a JavaScript framework like Angular or Polymer, where the HTML page is pretty plain and doesn’t contain much site content, then the cached page will also be very sparse.
This presents issues for the indexing process. And it’s a major concern because of how common JavaScript is on the modern web. Many, many web pages need to execute JavaScript to make their content visible. The cached version of these pages may not always represent the content they display.
In addition, JavaScript-heavy sites are all but inaccessible if their servers go down. Ordinarily, if a site is not available due to a server or connectivity issue, people can view the site content in Google’s cache. Sites that use JavaScript, however, won’t be available in the cache. Not only that, they can’t render key page resources in the event of downtime.
The good news is that you can optimize the Googlebot’s caching functionality.
One way to force the Googlebot to ingest page content is to code your site in isomorphic JavaScript, which renders pages on the server first. The rendered version is then sent to users. It’s thanks to a technology called Document Object Model (DOM) that Google can index dynamically generated content like this.
DOM is essentially an application programming interface, or API, for markup and structured data such as HTML and XML. It’s the interface that allows web browsers to assemble structured documents. The DOM also defines how that structure is accessed and manipulated.
The DOM represents the interface, or “bridge,” that connects web pages and programming languages. The HTML is parsed, JavaScript is executed, and the result is the DOM. The content that gets cached is not just source code, it’s the DOM. This makes the DOM extremely valuable.
What if you want to restrict caching for certain pages? This is an option, too.
Take the Wall Street Journal, which limits the number of free articles visitors can read. Because the Journal knows that some people would try to access articles, like this one, via Google’s cache, it limits page caching altogether:
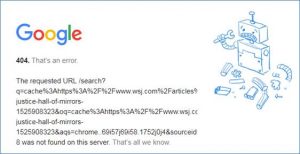
Is the page still being indexed to maximize “SEO juice”? Yes. Just because a page doesn’t get cached doesn’t mean that it can’t be indexed:
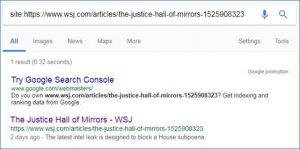
A simple piece of HTML instructs Google to index pages but not cache them: <meta name=”robots” content=”noarchive” />. This is another great example of how you optimize the Googlebot and put it to work.


